AI support for ORKG
We often get asked why we cannot just use AI models to fill the ORKG with data. The reason is that we need high quality data for science and AI models are not precise enough and sometimes even make up answers entirely. However, AI models can be useful in supporting ORKG workflows in various ways. In this tutorial, we show you how you can use AI to aid your work with the ORKG.
Leveraging ChatGPT for ORKG
This article offers some recommendations and tips on how ChatGPT can be leveraged by ORKG users to create ORKG Comparisons. The article is a walk-through over some examples of constructing ORKG Comparisons that we have tested on the chat interface.
What is ChatGPT?
ChatGPT is a conversational AI interface powered by the large language model (LLM) GPT-3.5 to generate responses as natural language text, code, or tables based on human-supplied prompts designed as questions or instructions. Its ability to generate tables when cleverly prompted is a feature that can be tapped into by ORKG users as an assistant to create their research comparisons.
Example 1 - Get a starting research comparison from ChatGPT given abstracts
The user has a starting set of papers to compare and wants suggestions for properties to compare the contributions in the papers by.
Prompt
Create a comparison table from the given text of the following three papers. Text of first paper: The early phase of the COVID-19 outbreak in Lombardy, Italy Abstract In the night of February 20, 2020 ... Text of second paper: Pattern of early human-to-human transmission of Wuhan 2019-nCoV Abstract On December 31, 2019, the ... Text of third paper: The basic reproduction number of COVID-19 across Africa Abstract The pandemic of the severe acute respiratory syndrome ...
Response
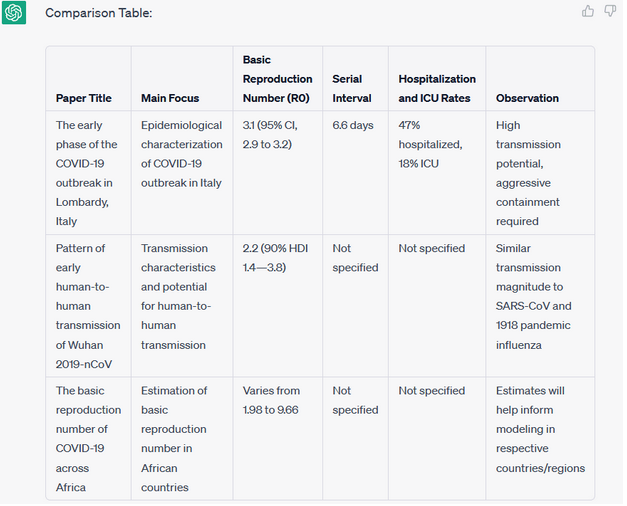
Here ChatGPT identified the Basic Reproduction Number (R0) property as the relevant comparison theme of the three paper contributions. The rest of the properties, however, are too vague, therefore undesirable to creating an ORKG research comparison.
Generally, an ORKG research comparison should based on a common research problem, which in this case is the Covid-19 reproduction number (R0) estimate, that unites the remaining properties as a theme. Based on this one property, the user can create a mental map of which other properties around the R0 estimate are relevant to describe fully as a structured research comparison an overview of the contributions. The next example elaborates this use-case.
Example 2 - Get a research comparison from ChatGPT given the comparison properties and abstracts as context
The user has a starting set of papers to compare and a starting set of properties to compare the contributions in the papers by.
Prompt
Create a comparison table from the given text of the following three papers. Text of first paper: The early phase of the COVID-19 outbreak in Lombardy, Italy Abstract In the night of February 20, 2020 ... Text of second paper: Pattern of early human-to-human transmission of Wuhan 2019-nCoV Abstract On December 31, 2019, the ... Text of third paper: The basic reproduction number of COVID-19 across Africa Abstract The pandemic of the severe acute respiratory syndrome ...
Response

There is more than one way to write a prompt. Here is another example.
Prompt
Create a comparison table on the theme of the Covid-19 basic reproduction number (R0) in Italy, China, and Africa based on the following properties: date, R0 value, % CI values, and method. Text of first paper: The early phase of the COVID-19 outbreak in Lombardy, Italy Abstract In the night of February 20, 2020 ... Text of second paper: Pattern of early human-to-human transmission of Wuhan 2019-nCoV Abstract On December 31, 2019, the ... Text of third paper: The basic reproduction number of COVID-19 across Africa Abstract The pandemic of the severe acute respiratory syndrome ...
Response
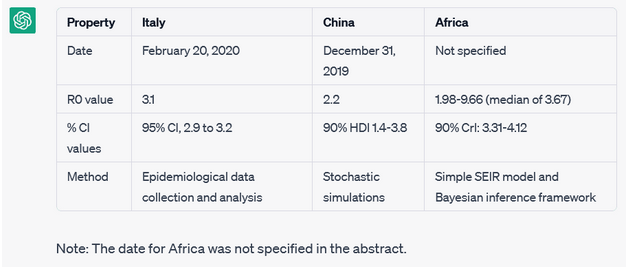
These comparisons are nearly 80% close to the final desirable ORKG Researh Comparison on the research problem of the Covid-19 R0 estimate which can be viewed here. With the ChatGPT result as a reference, the ORKG user is now equipped with the relevant information on data to create a structured ORKG research comparison.
Example 3 - How important is the context supplied?
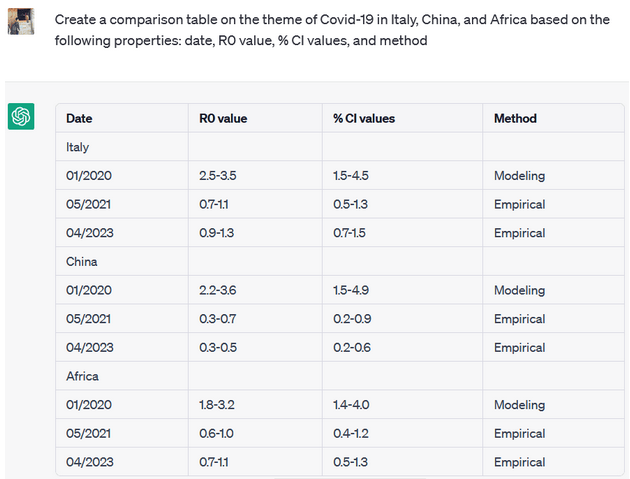
This comparison is created based on the knowledge base of the LLM which is not necessarily derived from the content of scholarly articles. Since the ORKG research comparisons are for scholarly articles, it is necessary to include in the prompt to ChatGPT the text of the article from which the research comparison can be created. Thus the above result is undesirable as an ORKG research comparison of the content described in scholarly articles.
In the case of what constitutes ideal context to prompt the model with, it is recommended to start with the article title and abstract. In case of undesirable results, additional sections of the article such as few lines from the Introduction, or Results, or Conclusions can also be tried.
Example 4 - Can ChatGPT help the ORKG user find related work toward creating a comparison on a given theme?
Prompt
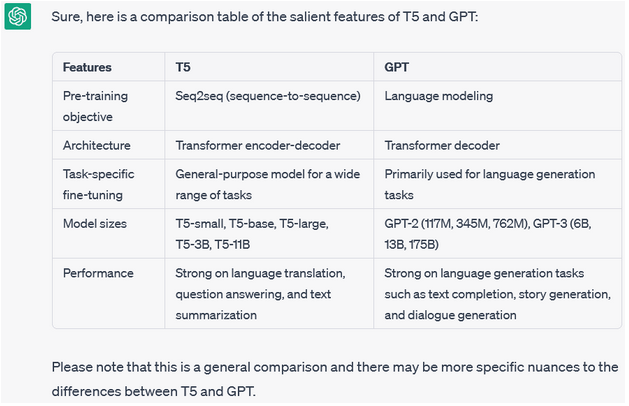
Can you generate a comparison table of the salient features of the following two transformer language models, viz. T5 and GPT?
Response
Follow-up Prompt
Please cite your sources.
Response

For problems that are well-known and extensively discussed in the community, ChatGPT works very well in creating structured comparisons and offering citations of related works as scholarly publications that are its knowledge sources. In this case, the cited articles 2 and 4 were the ones that introduced the models and that could be included as contribution items in an ORKG comparison.
A small caveat on the need to include enough context from scholarly articles in the prompt to ChatGPT to obtain an accurate set of properties to create ORKG comparisons. There maybe exceptions to this rule if the theme is one that is popular and known to be widely discussed in the community. This example on the theme of transformer language models is a case-in-point. Compare the ChatGPT result above with the ORKG Research Comparison that catalogs 60 different LLMs here. The ORKG comparison is based on the following properties: model name, model family, pretraining architecture, pretraining task, extension, application,date created, number of parameters, training corpus, organization, has source code, and blog post. Comparing these properties with the ChatGPT response, we find that ChatGPT offered an accurate, albeit less detailed, response on the comparable properties of transformer models. The ORKG user could have easily based their work on the properties recommended by ChatGPT to create an ORKG comparison on this widely discussed theme of transformer models.
Example 5 - ChatGPT can hallucinate information
It is recommended to observe caution with using ChatGPT as it can hallucinate information which if integrated without verification in the ORKG can lead to the problem of misinformation.
An important aspect of structuring contributions about machine learning models are the results obtained by the models. Such information is vital to the ORKG Benchmarks feature that compares the performances of machine learning models in Leaderboards. Sometimes a user might find it tedious to scour through the entire paper to find the model results, in particular if the work is not theirs. In which case, ChatGPT might potentially be leveraged as an assistant as in the case below.

Unfortunately, in this case, we were not so lucky with the result as everything in the ChatGPT response from the model names to the scores reported are hallucinated or made up. The following screen shows a follow-up prompt where we we probed the model to cite the source article whose title was used in the original prompt.

It was observed that, aside from getting the venue of the publication right, again the list of authors and the publication date are hallucinated or made-up information.
Researchers at the moment speculate that large LLMs may simply be learning heuristics, via an internal, statistics-driven process, that are out of reach for those with fewer parameters or lower-quality data which means drive their impressive capabilites. Thus models like ChatGPT, albeit very convincing, cannot be relied on 100% in performing desired tasks. In other words, the model pitfalls are it can be veered incorrectly based on the statistical patterns it accrued. Nevertheless, as demonstrated in the other examples above, it can indeed be a nice assistant to the ORKG user to create ORKG research comparisons.
Finally, here are some question suggestions that users can pose to ChatGPT to help them get started with the process of conceptualizing an ORKG research comparison.
-
Explain Field X.
-
Tell me which question drives Field X.
-
Which keywords are relevant for Field X?
-
Tell me what this paper is about: {input text}
-
Tell me what paper X is about
Additional Prompts
For more examples of prompts showing how ChatGPT can assist with ORKG content creation, we recommend reading the following Medium article Structured Scholarly Knowledge - ChatGPT Prompts You Need.
Using ChatGPT in the ORKG with Smart Suggestions
ChatGPT is rapidly gaining popularity and is used for a wide range of applications. Also for the ORKG, ChatGPT is a perfect match. One of the main tasks of users entering data in the ORKG, is reading articles, extracting knowledge presented within the article, and finally entering this in the ORKG. Since ChatGPT is very capable in dealign with natural language, also for the tasks that ORKG users perform, ChatGPT is an very suitable assistant.
There are many different approaches of integrating ChatGPT into the UI workflows. The method described in this article integrates ChatGPT in a non-intrusive way into the existing ORKG workflow. This means that you can start benefitting from the integration while still using the interfaces you are familiar with. We will now discuss how you can use the ChatGPT integration within ORKG.
General ChatGPT suggestions box
You can recognize the availability of ChatGPT support by the green lightbulb button, as displayed below.

Since ChatGPT provides you smart suggestions, we called the suggestion box Smart suggestions. The Smart suggestions box looks always similar, which you can see below.

The Explanation provides a short description what the suggestions are taking as input and what is the provided output. The Suggestions themselves are listed below. The Help button takes you to this page. The Reload button is helpful in case you want to get different suggestions. This can also be helpful if for some reason the suggestions aren’t displayed correct. Finally, Feedback is giving you the opportunity to provide feedback about the specific suggestions. This is very important for us, as it helps us to further improve the ChatGPT integrations. Below, you can see how the feedback form can be filled out.
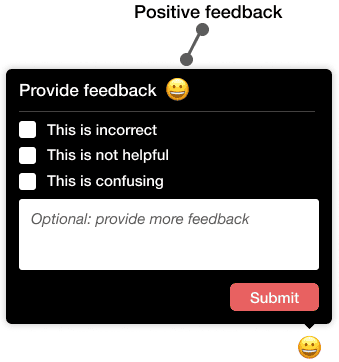
Your feedback is very valuable for us, so would like to ask you to actively fill out the feedback form when using this functionality. It is very helpful if you provide feedback multiple times, as each case is different.
Use cases
As mentioned before, ChatGPT is integrated in a similar manner throughout the ORKG website. However, the suggestions themselves are very different. In total, we created 6 use cases where ChatGPT is used. In the future, we hope to add additional use cases. Below the use cases are explained in more detail.
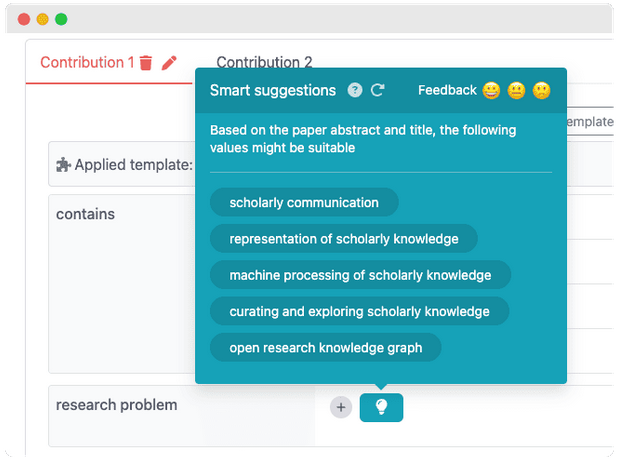
Value suggestions
For a selected set of properties, the Smart suggestions appear to provide a list of suggestions resources. The suggestions are generated based on the title and abstract of a paper. Currently, the Smart suggestions are only displayed for the following properties: research problem, method, and material. Only when visiting the View paper page, the light button button appears, e.g., it does not appear on the resource page.
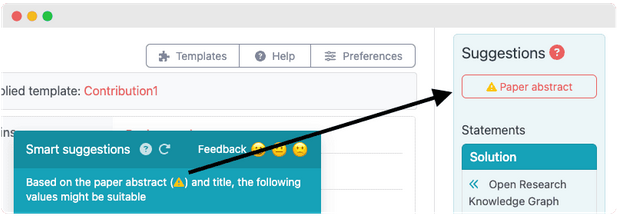
Tip: when the abstract is not found automatically, you will see an exclamation mark after the word abstract in the modal (see image below). To get better suggestions, you can manually provide the abstract by clicking the "Paper abstract" button in the "Suggestions" box on the right side.
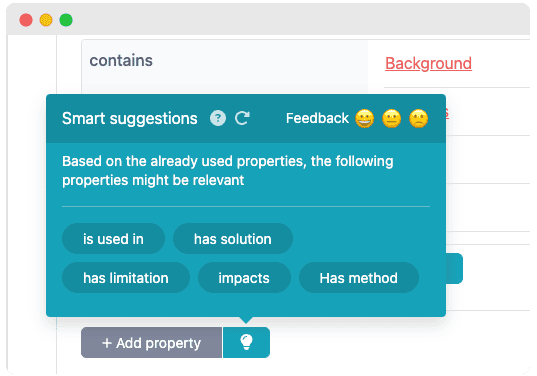
Property suggestions
Properties are suggested based on the existing properties that are added. Therefore, the suggestions can only be used if there are already existing properties added. The suggestions appear next to the Add property button, both on the View paper page and within the Contribution editor.
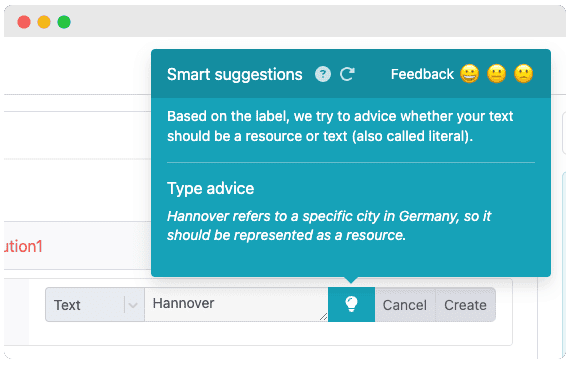
Feedback on whether text should be a resource
Sometimes it is hard to determine whether some piece of text should be stored as a resource or as text (generally, if you, or anyone else, can reuse this piece of information, you can use a resource). The Smart suggestion here is helping you to decide what is the best type to choose. Since there is no clear right and wrong, ChatGPT will only give feedback and not a final correctness core. You find this Smart suggestion while adding a value of type, Text, Number, Date, etc.
Feedback on resource structure
When creating a resource, it is sometimes possible to decompose your resource to make it atomic. As a concrete example, the resource "120 participants between 45-65 recruited online" can be decomposed into several resources (about the number of participants, their age, and the method of recruitment). The Smart suggestions provide feedback on whether it indeed makes sense to decompose your resource into several resources. You find this Smart suggestion while adding a value of type Resource.
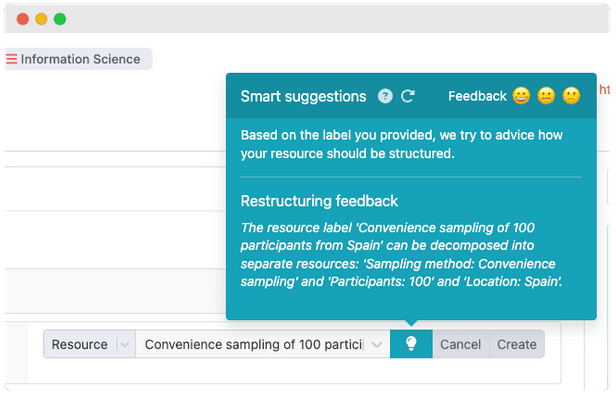
Tip: sometimes when reloading the suggestions, the opinion of ChatGPT changes. This means that one time no restructuring is needed, while after clicking the Reload button, the restructuring is recommended. So use the suggestions from ChatGPT as inspiration, and not as facts.
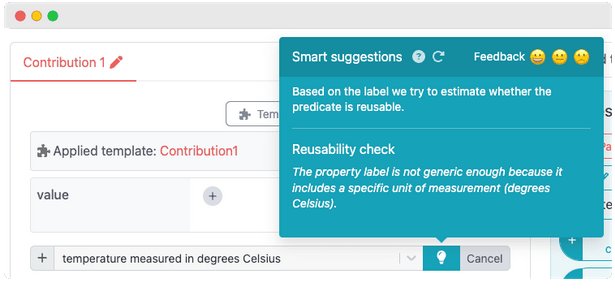
Feedback on property reusability
When creating new properties, it is best to provide a generic label. This makes it possible for others to reuse properties more easily. See the [modeling best practices] for more information. ChatGPT checks whether a property label is indeed generic enough to make it reusable. You will find this Smart suggestion when creating a new property.
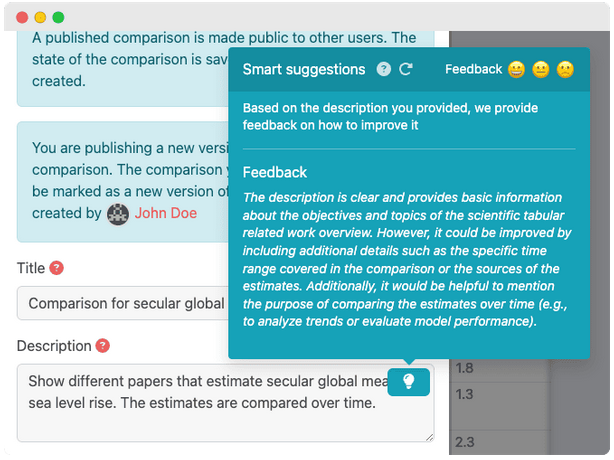
Feedback on comparison descriptions
When publishing a comparisons, it is best practice to provide a clear description of the comparison objectives. We integrated ChatGPT here to provide feedback and some inspiration to improve your description. Currently, this Smart suggestion is only displayed in the Publish comparison popup.
Known Issues
I get "Failed to fetch recommendations. Try again."
This can happen because of several different reasons. Most likely the response from ChatGPT could not be parsed. This sometimes is caused by the input data (e.g. a too short label, missing description etc.). Try updating the input data and try it again. Otherwise, try it again later.
The recommendations are inaccurate / wrong
It is indeed very possible that recommendations are wrong. This is one of the reasons why human validation is still needed, and why this process doesn’t happen fully automatically. When results are wrong, feel free to ignore them. Of course, it is always helpful to provide feedback about your specific case.